20.5 Rattle Summary of Dataset
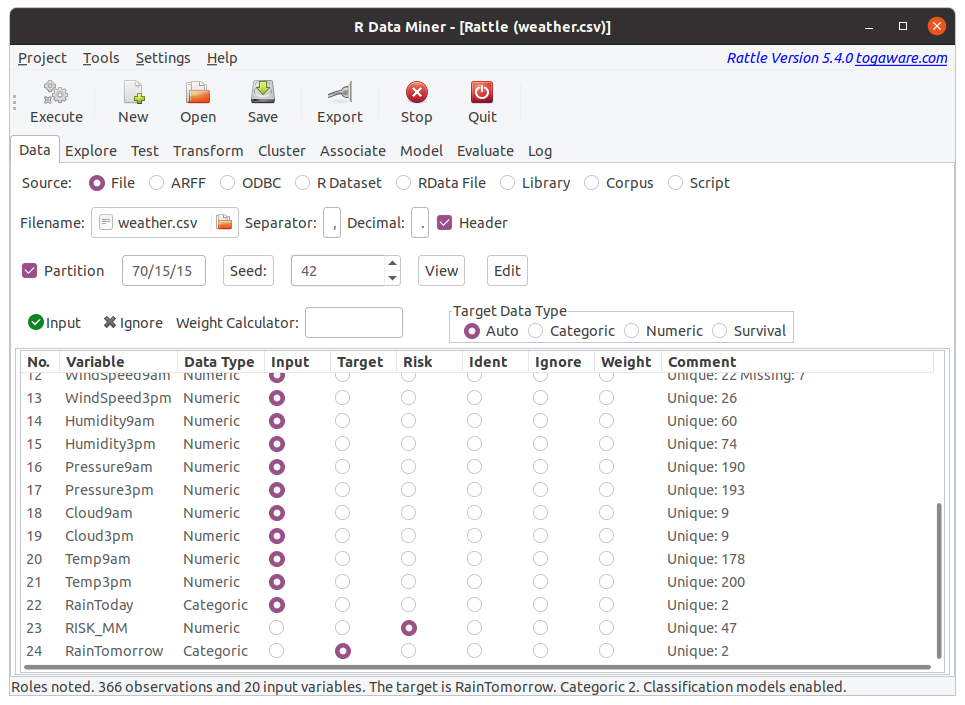
The dataset from consists of daily observations of various weather related data over one year at one location (Canberra Airport). Each observation has a date and location. These are the id variables for this dataset.
The observations include the temperature during the day, humidity, the number of hours of sunshine, wind speed and direction, and the amount of evaporation. These are the input variables for this dataset.
Together with each day’s observations we record whether it rains the following day and how much rain was received. These will be the target variables for this dataset.
Scroll through the list of variables to notice that default roles have been assigned to each of the variables. Rattle deploys some heuristics to decide on the roles, particularly the target and risk variables.
Your donation will support ongoing availability and give you access to the PDF version of this book. Desktop Survival Guides include Data Science, GNU/Linux, and MLHub. Books available on Amazon include Data Mining with Rattle and Essentials of Data Science. Popular open source software includes rattle, wajig, and mlhub. Hosted by Togaware, a pioneer of free and open source software since 1984. Copyright © 1995-2022 Graham.Williams@togaware.com Creative Commons Attribution-ShareAlike 4.0
