7.3 kmeans demo
20211016
The pre-built demonstration highlights the capabilities of the package.
==========================
K-Means Algorithm Showcase
==========================
K-means is an unsupervised clustering algorithm which does not require
any pre-labelled data to build a model. The algorithm groups data into k
clusters, each represented by its cluster centroid. The user needs to
provide the value of k (the number of clusters).
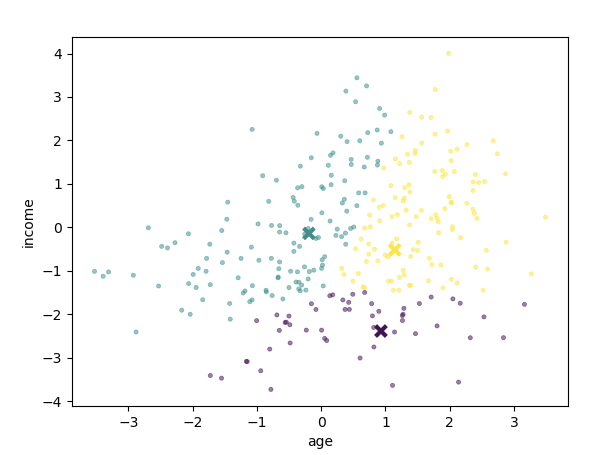
Our first example will build a clustering for a random dataset (a
different one each time) consisting of two variables, age and income,
for each person. The task begins by randomly choosing k (3) centroids
(shown as X's in the graphic). Each point is also coloured according to
its nearest centroid.
Close the graphic window using Ctrl-W.
Press Enter to continue: The following graphic is displayed by the demo and the demo then waits
for the user to indicate to continue with the demonstration, by typing
the Enter key.
Your donation will support ongoing availability and give you access to the PDF version of this book. Desktop Survival Guides include Data Science, GNU/Linux, and MLHub. Books available on Amazon include Data Mining with Rattle and Essentials of Data Science. Popular open source software includes rattle, wajig, and mlhub. Hosted by Togaware, a pioneer of free and open source software since 1984. Copyright © 1995-2022 Graham.Williams@togaware.com Creative Commons Attribution-ShareAlike 4.0
